NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
Laburpena
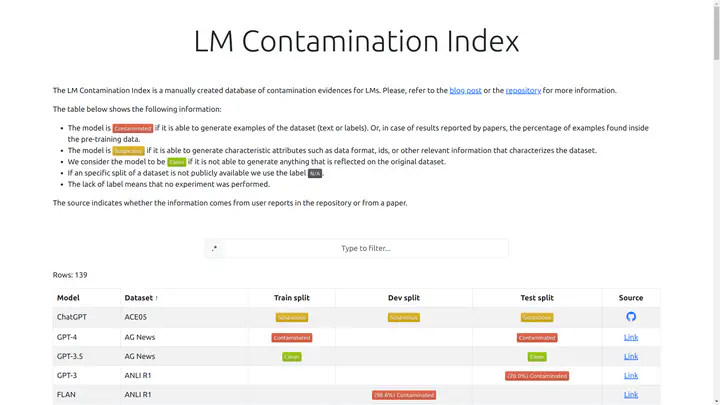
In this position paper, we argue that the classical evaluation on Natural Language Processing (NLP) tasks using annotated benchmarks is in trouble. The worst kind of data contamination happens when a Large Language Model (LLM) is trained on the test split of a benchmark, and then evaluated in the same benchmark. The extent of the problem is unknown, as it is not straightforward to measure. Contamination causes an overestimation of the performance of a contaminated model in a target benchmark and associated task with respect to their non-contaminated counterparts. The consequences can be very harmful, with wrong scientific conclusions being published while other correct ones are discarded. This position paper defines different levels of data contamination and argues for a community effort, including the development of automatic and semi-automatic measures to detect when data from a benchmark was exposed to a model, and suggestions for flagging papers with conclusions that are compromised by data contamination.
Julen Etxaniz
Hizkuntzaren Azterketa eta Prozesamendua Doktoregoko ikaslea
Hizkuntzaren Azterketa eta Prozesamendua Doktoregoko ikaslea HiTZ Zentroko IXA taldean (UPV/EHU). Hizkuntza ereduak baliabidea urriko hizkuntzetako hobetzeko lanean. Informatika Ingeniaritzan graduatua Software Ingeniaritza espezialitatearekin. Hizkuntzaren Azterketa eta Prozesamendua Masterra.